微软版Sora诞生了!
Sora虽爆火但闭源,给学术界带来了不小的挑战。学者们只能尝试使用逆向工程来对Sora复现或扩展。
尽管提出了DiffusionTransformer和空间patch策略,但想要达到Sora的性能还是很难,何况还缺乏算力和数据集。
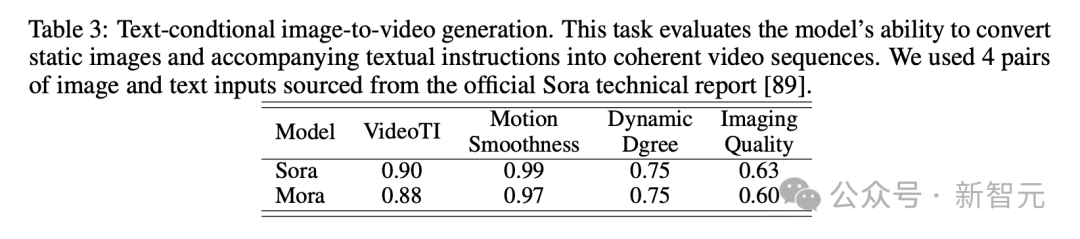
不过,研究者发起的新一波复现Sora的冲锋,这不就来了么!
就在刚刚,理海大学联手微软团队一种新型的多AI智能体框架———Mora。

论文地址:
没错,理海大学和微软的思路,是靠AI智能体。
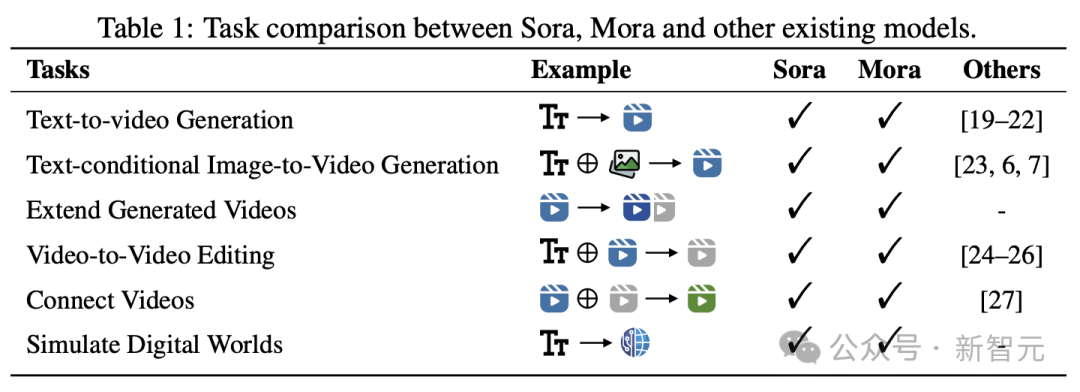
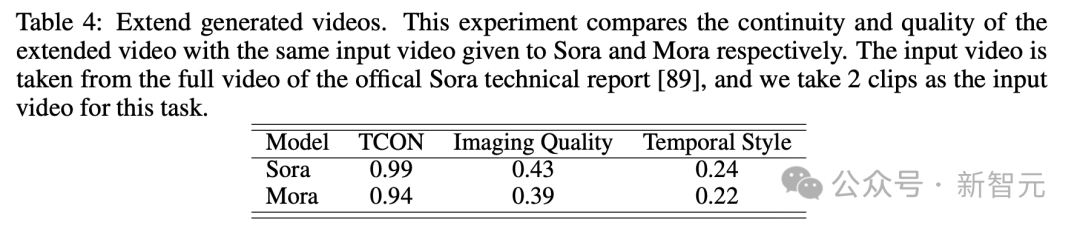
-扩展已生成视频
-拼接视频
-模拟数字世界

实验结果表明,Mora在这些任务中取得了接近Sora的表现。
不过,在整体性能上,与Sora还有着明显差距。

复刻Sora所有能力
Mora基本上还原了Sora的所有能力,怎么体现?

提示:Avibrantcoralreefteemingwithlifeunderthecrystal-clearblueocean,withcolorfulfishswimmingamongthecoral,raysofsunlightfilteringthroughthewater,andagentlecurrentmovingtheseaplants.
提示:Amajesticmountainrangecoveredinsnow,withthepeakstouchingthecloudsandacrystal-clearlakeatitsbase,reflectingthemountainsandthesky,creatingabreathtakingnaturalmirror.

提示:Inthemiddleofavastdesert,agoldesertcityappearsonthehorizon,,whileintheair,seve
输入这张经典的「SORA字样的逼真云朵图像」。
提示:Animageofarealisticcloudthatspells“SORA”.
Sora模型生成的效果是这样的。
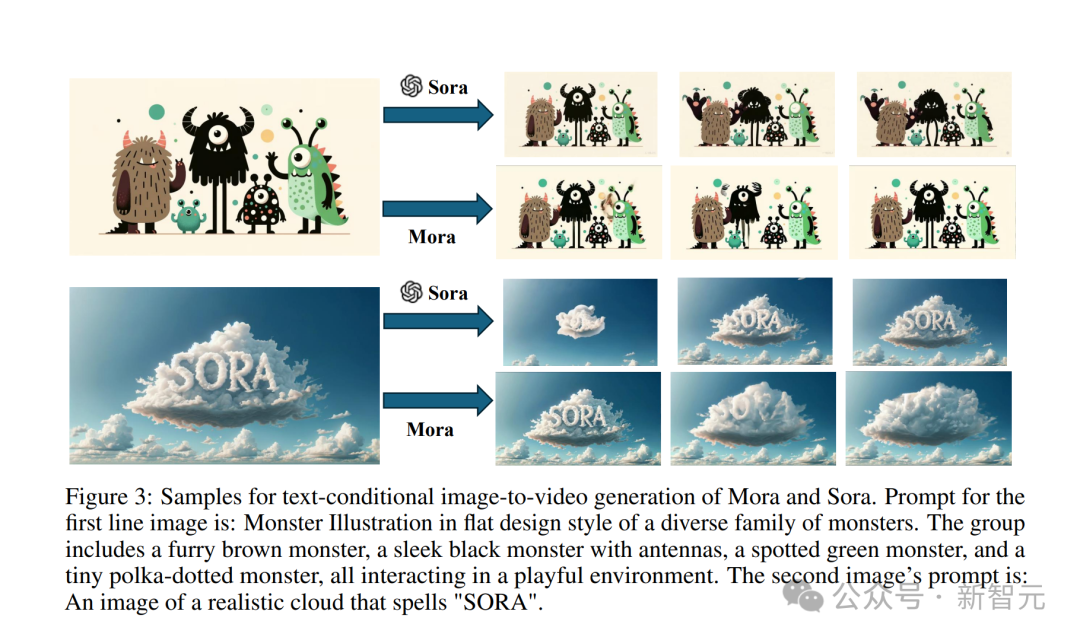
还有输入一张小怪兽图片。

提示:,asleekblackmonsterwithantennas,aspottedgreenmonster,andatinypolka-dottedmonster,allinteractinginaplayfulenvironment.
Mora虽也让小怪兽们动起来,但是明显可以看出有些不稳定,图中卡通人物样子没有保持一致。

扩展已生成的视频
先给到一个视频



Sora经过风格替换后,整体看起来非常丝滑。
Mora这段老式汽车的生成,破旧的有点不真实。


Mora拼接后的视频
模拟数字世界

整体接近,但不如Sora
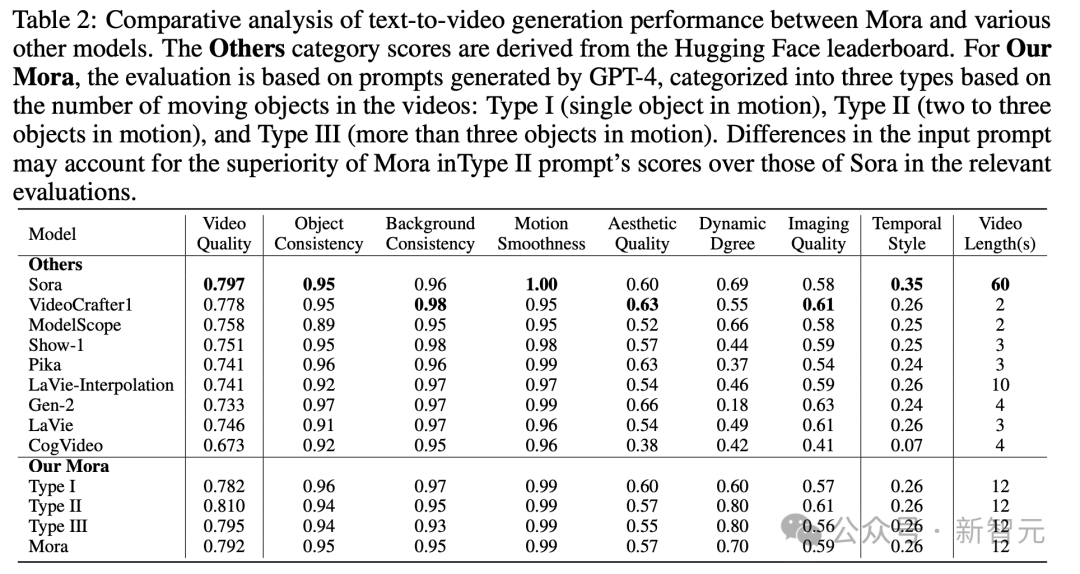
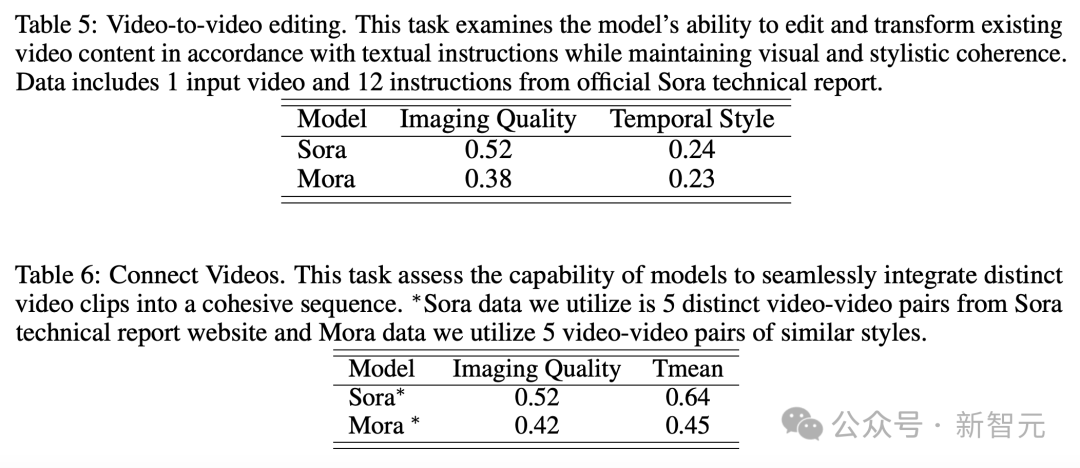
与OpenAISora相比,Mora在六个任务中的表现非常接近,不过也存在着很大的不足。
不过Mora的结果,与Sora相差很小。
扩展生成的视频
在这个示例中,Sora和Mora都被指示将设置修改为1920年代风格,同时保持汽车的红色。
模拟数字世界
还有最后的模拟数字世界的任务,Mora也能像Sora一样具备创建虚拟环境世界的能力。不过质量方面,比Sora差一些。
总结来说,团队的主要贡献如下:
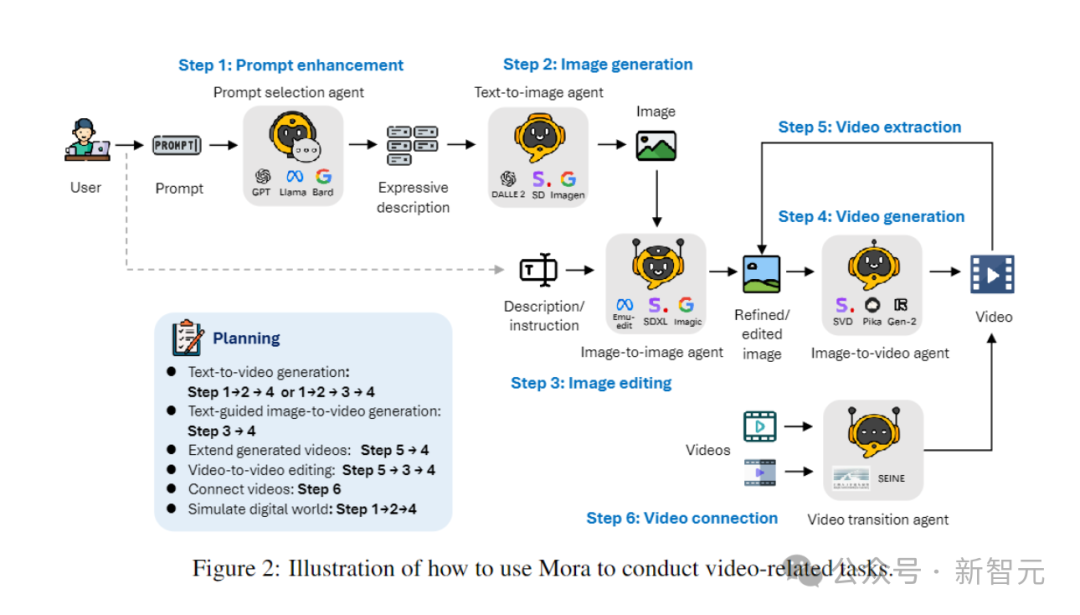
-创新性的多智能体框架,以及一个直观的界面,方便用户配置不同的组件和安排任务流程。
智能体的定义-提示选择与生成智能体:
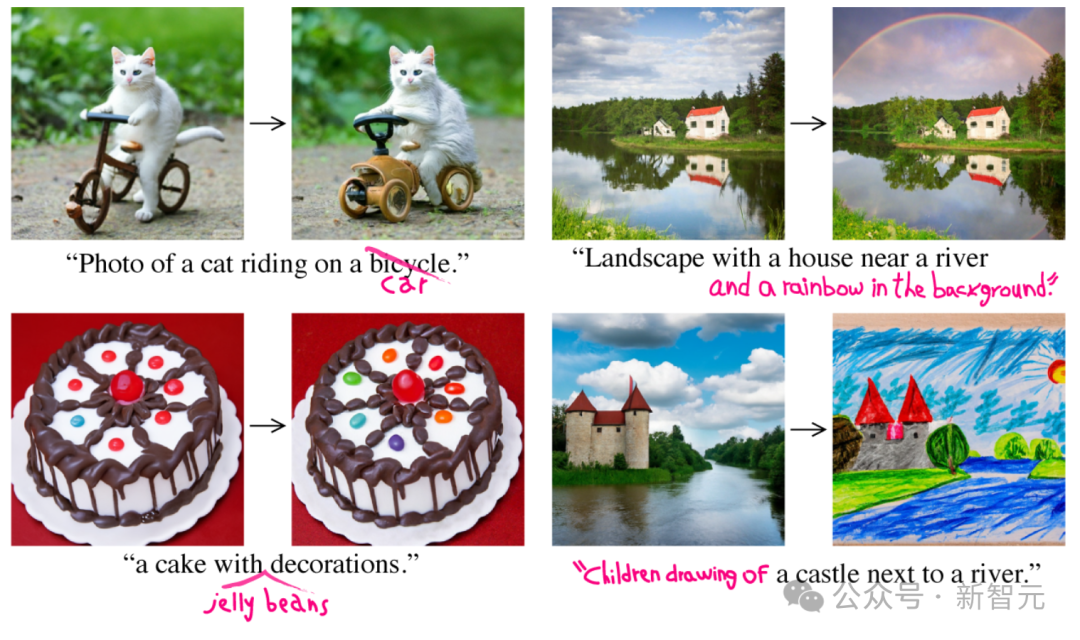
在开始生成初始图像之前,文本提示会经过一系列严格的处理和优化步骤。这个智能体可以利用大型语言模型(如GPT-4)来精确分析文本,提取关键信息和动作,大大提高生成图像的相关性和质量。
-文本到图像生成智能体:
这个智能体负责将丰富的文本描述转化为高质量的图像。它的核心功能是深入理解和可视化复杂的文本输入,从而能够根据提供的文本描述创建详细、准确的视觉图像。
-图像到图像生成智能体:
根据特定的文本指令修改已有的源图像。它能够精确解读文本提示,并据此调整源图像(从细微修改到彻底改造)。通过使用预训练模型,它能够将文本描述与视觉表现有效拼接,实现新元素的整合、视觉风格的调整或图像构成的改变。
智能体的实现文本到图像的生成
研究者利用预训练的大型文本到图像模型,来生成高质量且具有代表性的第一张图像。
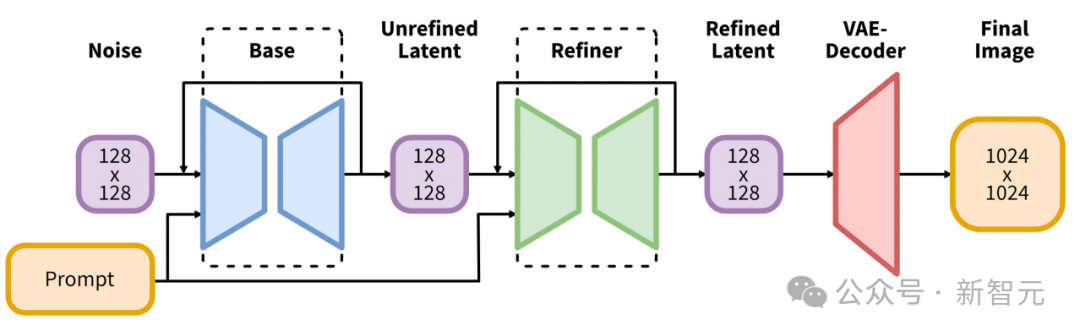
第一个实现,用的是StableDiffusionXL。
它引入了文本到图像合成的潜在扩散模型的架构和方法的重大演变,在该领域树立了新的基准。
其架构的核心,就是一个扩大的UNet主干网络,它比StableDiffusion2之前版本中使用的主干大三倍。
这种扩展主要是通过增加注意力块的数量和更广泛的交叉注意力上下文来实现的,并通过集成双文本编码器系统来促进。
第一个编码器基于OpenCLIPViT-bigG,而第二个编码器则利用CLIPViT-L,通过拼接这些编码器的输出,来允许对文本输入进行更丰富、更细致的解释。
这种架构创新辅以多种新颖的调节方案的引入,这些方案不需要外部监督,从而增强了模型的灵活性和生成跨多个长宽比的图像的能力。
此外,SDXL还具有一个细化模型,该模型采用事后图像到图像转换来提高生成图像的视觉质量。
此细化过程利用噪声去噪技术,进一步完善输出图像,而不会影响生成过程的效率或速度。
图像到图像的生成
在这个过程中,研究者用初始框架,实现了使用InstructPix2Pix作为图像到图像生成智能体。
InstructPix2Pix经过精心设计,可以根据自然语言指令进行有效的图像编辑。
该系统的核心集成了两个预训练模型的广泛知识:GPT-3用于根据文本描述生成编辑指令和编辑后的标题;StableDiffusion用于将这些基于文本的输入转换为视觉输出。
这种巧妙的方法首先在精选的图像标题数据集和相应的编辑指令上微调GPT-3,从而产生一个可以创造性地建议合理编辑并生成修改后的标题的模型。
在此之后,通过Prompt-to-Prompt技术增强的StableDiffusion模型,会根据GPT-3生成的字幕生成图像对(编辑前和后)。
然后在生成的数据集上训练InstructPix2Pix核心的条件扩散模型。
InstructPix2Pix直接利用文本指令和输入图像,在单次前向传递中执行编辑。
通过对图像和指令条件采用无分类器指导,进一步提高了这种效率,使模型能够平衡原始像的保真度和遵守编辑指令。
SVD模型的核心遵循三阶段训练体系,从文本到图像相关开始,模型从一组不同的图像中学习稳健的视觉表示。这个基础,使模型能够理解并生成复杂的视觉图案和纹理。
SEINE是基于预训练的T2V模型LaVie智能体构建的。
讨论
优势-创新框架与灵活性:
-开源贡献:
Mora的开源特性是对AI社区一个重要的贡献,它通过提供一个坚实的基础,鼓励进一步的发展和完善,为未来的研究奠定了基础。
局限性-质量与长度的差距:
-指令跟随能力:
此外,Mora还不能控制对象的运动方向,比如无法让对象向左或向右移动。
-人类偏好对齐: